
Every B2B SaaS marketer using AI for content has an opinion on the ChatGPT vs Claude debate. Most of those opinions are based on vibes, not evidence. So we ran a structured test: seven identical prompts, both tools, judged on criteria that actually matter for B2B SaaS content specifically. Furthermore, we applied the same standards we use when reviewing SaaS content marketing agencies for our own roundups.
No feature comparisons. No pricing breakdowns. Just outputs, side by side, scored honestly.
How we ran the test
Seven tasks, identical prompts in both tools, no extra context given beyond what was in the prompt. Each output was judged on five criteria:
- Specificity : does it avoid generic filler?
- Tone accuracy : does it match the brief?
- B2B SaaS awareness : does it understand the context?
- Human-sounding : would a reader know it was AI?
- First draft usability : could you publish this with minimal edits?
Each criterion scored 1 to 5. Maximum score per test: 25. Maximum overall: 175.
Test 1: Blog intro
The brief: Write an intro paragraph for “How to Build a B2B SaaS Content Calendar That Drives Pipeline.” Focus keyword: B2B SaaS content calendar. Target reader: Head of Marketing at a Series B SaaS company. Tone: direct, opinionated, no fluff. Under 120 words. This is the same brief used to write our B2B SaaS content calendar guide.
ChatGPT Response
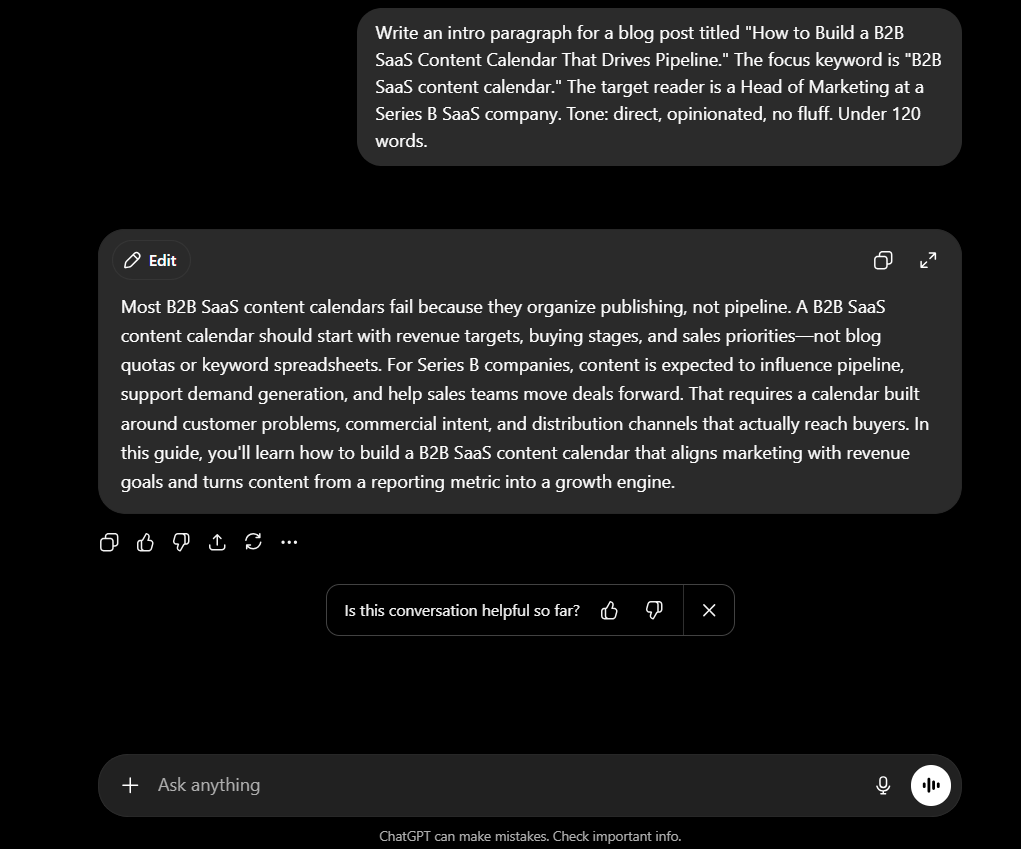
ChatGPT opened with a clear statement of the problem: most B2B SaaS content calendars organise publishing rather than pipeline. It named the right elements : revenue targets, buying stages, sales priorities and positioned the post correctly for a Series B audience. The structure is logical, the keyword lands in the first sentence, and the closing line promises a clear outcome. It is competent, well-organised, and safe. However it is not sharp. The voice reads like a confident marketer summarising a topic, but not a peer speaking directly to the reader’s daily frustration.
Claude Response
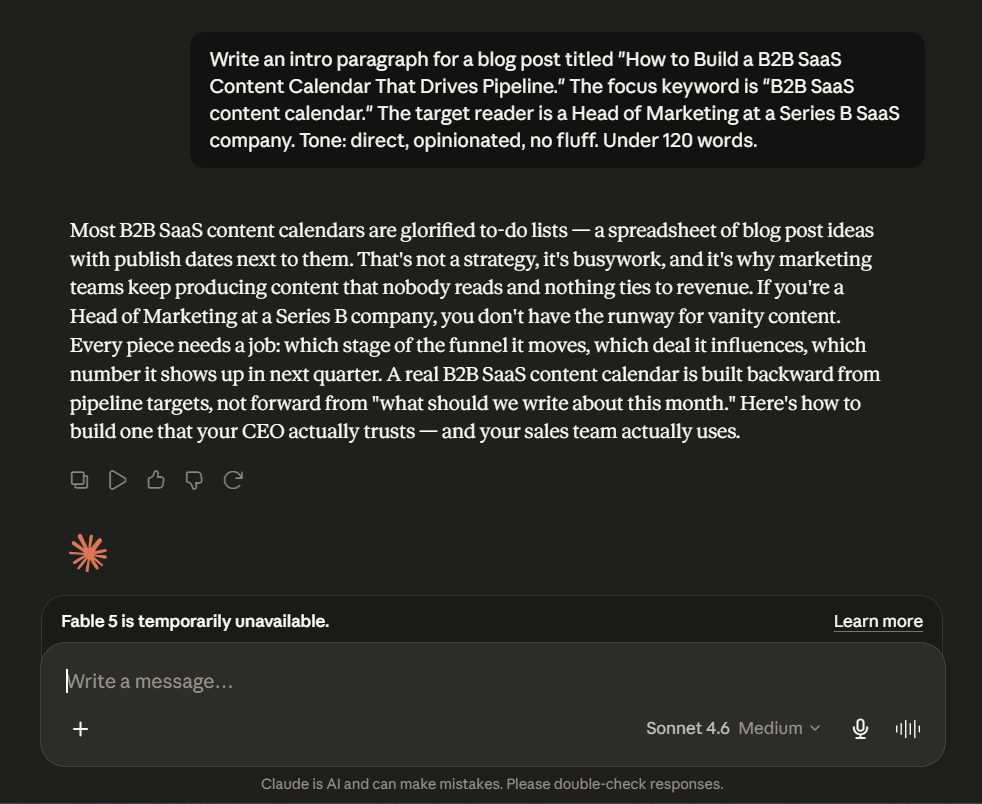
Claude opened with a provocation: “Most B2B SaaS content calendars are glorified to-do lists.” That is the kind of opening line a Head of Marketing reads and thinks “that is exactly what ours is.” The rest of the paragraph builds the stakes specifically for a Series B reader : no runway for vanity content, every piece needs a job, before landing on a closing line that promises both strategic credibility and practical buy-in from two audiences that rarely agree: the CEO and the sales team. The keyword appears naturally. The voice is opinionated without being aggressive. Consequently, it earns the scroll.
Verdict: Both understood the brief. ChatGPT told the reader what the post is about. Claude made the reader feel the problem. For a B2B SaaS audience that reads dozens of content marketing posts, the difference between those two approaches determines whether the post gets read or closed.
| Criterion | ChatGPT | Claude |
| Specificity | 4 | 5 |
| Tone accuracy | 5 | 5 |
| B2B SaaS awareness | 4 | 5 |
| Human-sounding | 3 | 3 |
| First draft usability | 4 | 4 |
| Total | 20 | 22 |
Test 2: Editorial bullets
The brief: Write a “Why it made our list” section for a fictional B2B SaaS content marketing agency called GrowthLayer. Four bullet points, editorial tone, 1-2 sentences each, no filler phrases like “cutting-edge” or “innovative.” (GrowthLayer is fictional here, does not refer to any particular company)
ChatGPT Response
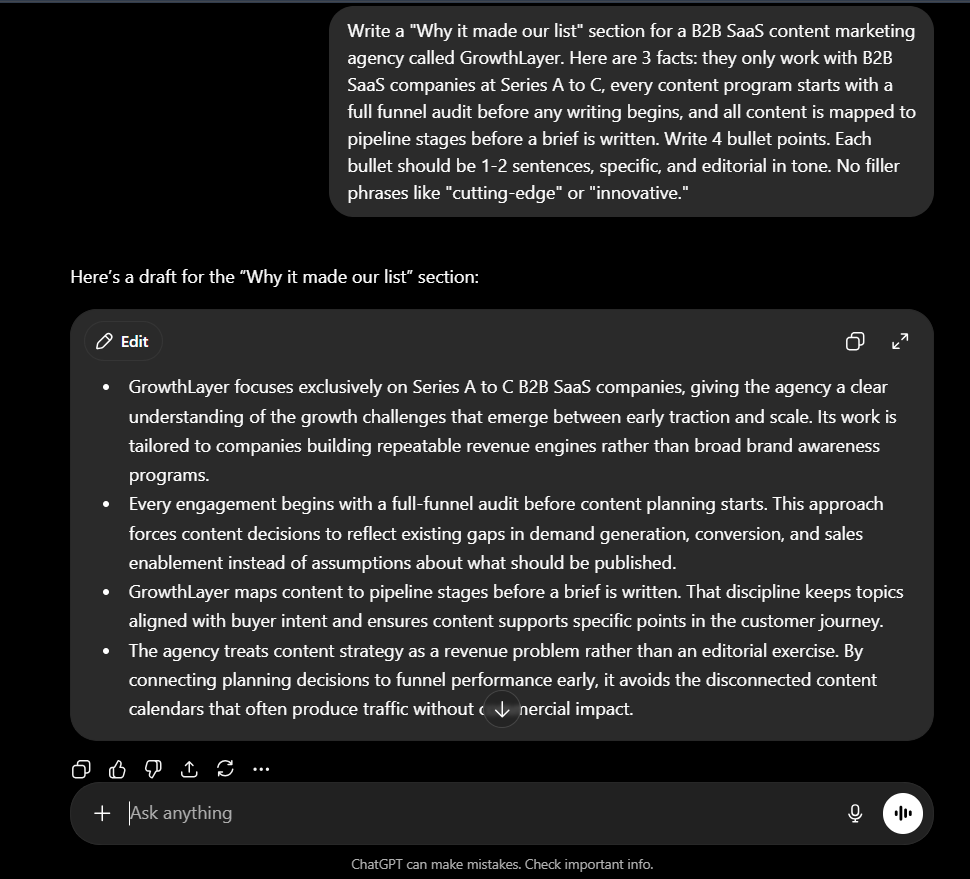
ChatGPT produced four clean, readable bullets that accurately reflected the three facts given in the brief. Each point supported its claim with a second sentence that added context. The writing is professional and clear. However, the framing stayed descriptive throughout, it explained what GrowthLayer does without making the reader feel why it matters. Phrases like “gives the agency a clear understanding of the growth challenges” and “forces content decisions to reflect existing gaps” are accurate but passive. They describe a process rather than advocate for a result.
Claude Response
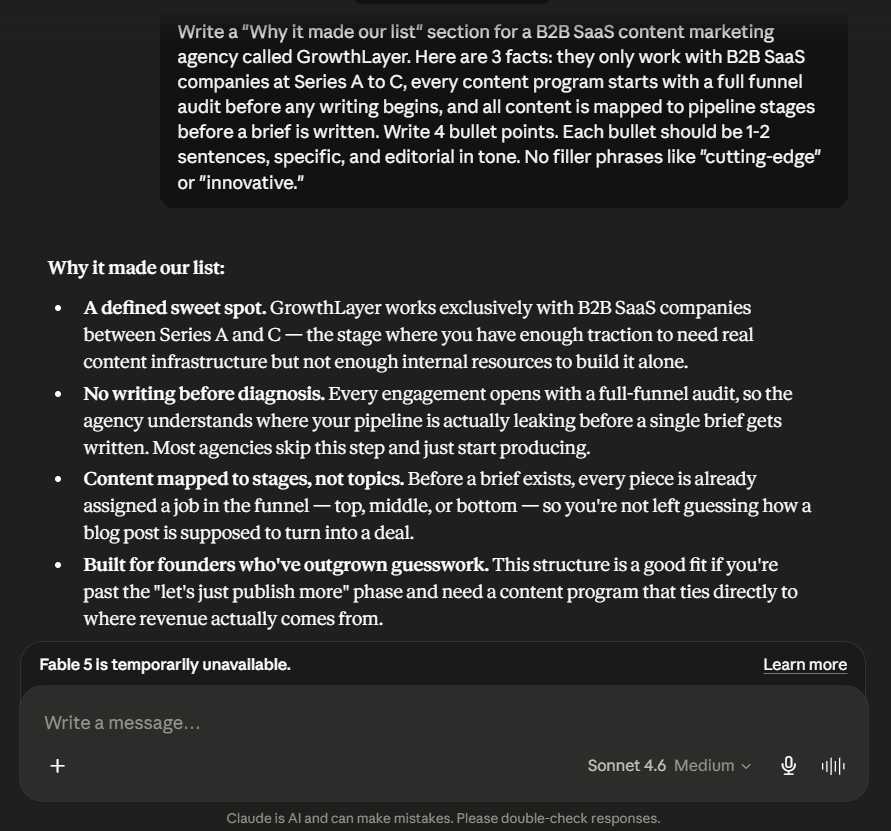
Claude led with bold labels that do editorial work before the reader even finishes the first word: “A defined sweet spot,” “No writing before diagnosis,” “Content mapped to stages, not topics,” “Built for founders who’ve outgrown guesswork.” Each label is a claim, not a category. The supporting sentences then use the facts from the brief to prove the claim rather than simply restate it. The line “Most agencies skip this step and just start producing” is the kind of editorial observation that earns credibility with a sceptical B2B reader, because it is true and most agencies would not say it. However there is a lot of use of em-dashes and that’s not considered good.
Verdict: ChatGPT was accurate and structured. Claude was editorial. For a listicle designed to influence a buying decision, editorial wins. The difference is between describing an agency and advocating for one. Moreover, Claude’s bullets would require almost no editing before publishing. ChatGPT’s would need a reframe pass.
| Criterion | ChatGPT | Claude |
| Specificity | 4 | 5 |
| Tone accuracy | 4 | 5 |
| B2B SaaS awareness | 4 | 4 |
| Human-sounding | 4 | 3 |
| First draft usability | 4 | 5 |
| Total | 20 | 22 |
Test 3: Paragraph rewrite
The brief: Rewrite a weak, generic paragraph about content marketing for SaaS. Make it more direct, specific, and useful for a B2B SaaS marketer. Remove filler. Keep it under 80 words.
ChatGPT Response
ChatGPT produced a clean rewrite that correctly identified pipeline as the goal and positioned the funnel as the organising framework. The writing is tighter than the original and the ideas are more specific. However, it remained explanatory rather than instructional. It describes what good content marketing does rather than telling the reader what to do. The phrase “content only works when it is tied to customer problems, commercial intent, and measurable business outcomes” is accurate but reads like a definition, not a directive.
Claude Response
Claude rewrote the paragraph as an instruction with a consequence: map every piece to a buyer question, track it against pipeline not pageviews, and if you do not do this, the gap shows up in your CAC. The CAC reference is the key move here : it is a metric that B2B SaaS marketers defend to their CFO and their board, which means it carries real weight in a way “measurable business outcomes” does not. It is the same thinking behind SaaS content marketing metrics that actually matter. Notably, Claude was also more concise, landing the rewrite in fewer words without losing any substance.
Verdict: Both rewrites improved the original significantly. ChatGPT made it professional. Claude made it useful. For a B2B SaaS marketer, the CAC line alone makes Claude’s version the one worth saving.
| Criterion | ChatGPT | Claude |
| Specificity | 4 | 5 |
| Tone accuracy | 4 | 5 |
| B2B SaaS awareness | 4 | 5 |
| Human-sounding | 4 | 3 |
| First draft usability | 4 | 3 |
| Total | 20 | 21 |
Test 4: Meta description
The brief: Write a meta description for “10 Best SaaS Content Marketing Agencies for B2B in 2026.” Focus keyword: SaaS content marketing agencies. Must be between 140 and 155 characters including spaces. End with a subtle CTA.
ChatGPT Response
ChatGPT produced a meta description it self-reported as 154 characters. The actual output reads: “Compare the best SaaS content marketing agencies for B2B in 2026, including their strengths, services, and ideal fit. Explore the list.” That is 138 characters : below the 140-character minimum specified in the brief. The CTA (“Explore the list”) is present but generic. Furthermore, the description leads with a neutral verb (“Compare”) rather than a pain point, which misses the click-through opportunity for a high-intent search.
Claude Response
Claude produced a 144-character meta description: “Looking for SaaS content marketing agencies that drive real pipeline? Compare the top 10 B2B picks for 2026 and find your fit. See the list.” It hit the character range, led with a pain point framed as a question, and closed with a CTA that positions the reader as an active decision-maker (“find your fit”) rather than a passive browser. The focus keyword appears naturally. It is ready to paste into AIOSEO without editing.
Verdict: Claude hit the spec. ChatGPT missed it. A meta description outside the character range gets truncated or rewritten by Google, which means ChatGPT’s output would need a fix before it could be used. This is the starkest functional difference across all six written tests.
| Criterion | ChatGPT | Claude |
| Specificity | 3 | 4 |
| Tone accuracy | 3 | 4 |
| B2B SaaS awareness | 4 | 4 |
| Human-sounding | 4 | 4 |
| First draft usability | 3 | 4 |
| Total | 17 | 20 |
Test 5: Blog topic suggestions
The brief: Suggest 10 blog topics for a B2B SaaS content marketing agency targeting founders and heads of marketing at Series A to C companies. Topics should have clear search intent and pipeline value. No generic topics like “what is content marketing.”
ChatGPT Response

ChatGPT structured each topic with a title, target keyword, intent classification, and pipeline value rating. The format is useful and the organisation makes the list easy to evaluate. However, several topics were broad enough to be generic: “B2B SaaS content strategy” and “SEO for SaaS” are categories, not topics. The pipeline value ratings were self-declared rather than demonstrated. Furthermore, a few topics (“The Series B Content Playbook”) would require significant development before they could be turned into a brief.
Claude Response

Claude produced titles that are immediately search-ready and buyer-aware. “How Much Should a Series B SaaS Company Spend on Content Marketing?” targets a specific buying trigger. “In-House vs. Agency Content Team: A Cost Breakdown for B2B SaaS” targets a direct comparison search that sits right above a purchase decision. Each topic came with a one-line rationale explaining the search intent and the pipeline stage it serves. Claude also noted when a topic “sits right above the agency’s own buying decision” : demonstrating awareness of the commercial purpose of the content, not just the editorial one.
Verdict: ChatGPT gave a well-formatted list. Claude gave a strategically aware one. The topics Claude suggested also map cleanly to the kind of content distribution thinking that makes each post earn its place in a cluster. The difference is that Claude’s topics could be handed to a writer with the rationale intact and turned into briefs immediately. That is exactly what a well-written content brief enables. ChatGPT’s list would need a strategy pass first.
| Criterion | ChatGPT | Claude |
| Specificity | 3 | 5 |
| Tone accuracy | 4 | 4 |
| B2B SaaS awareness | 4 | 5 |
| Human-sounding | 4 | 4 |
| First draft usability | 4 | 4 |
| Total | 19 | 22 |
Test 6: LinkedIn post in founder voice
The brief: Write a LinkedIn post from a B2B SaaS founder’s perspective. Opinion: most SaaS companies attract the wrong audience by optimising for traffic instead of pipeline. Tone: direct, slightly contrarian, no hashtags, no emojis, under 150 words. Should sound like a real founder, not a marketing department.
ChatGPT Response
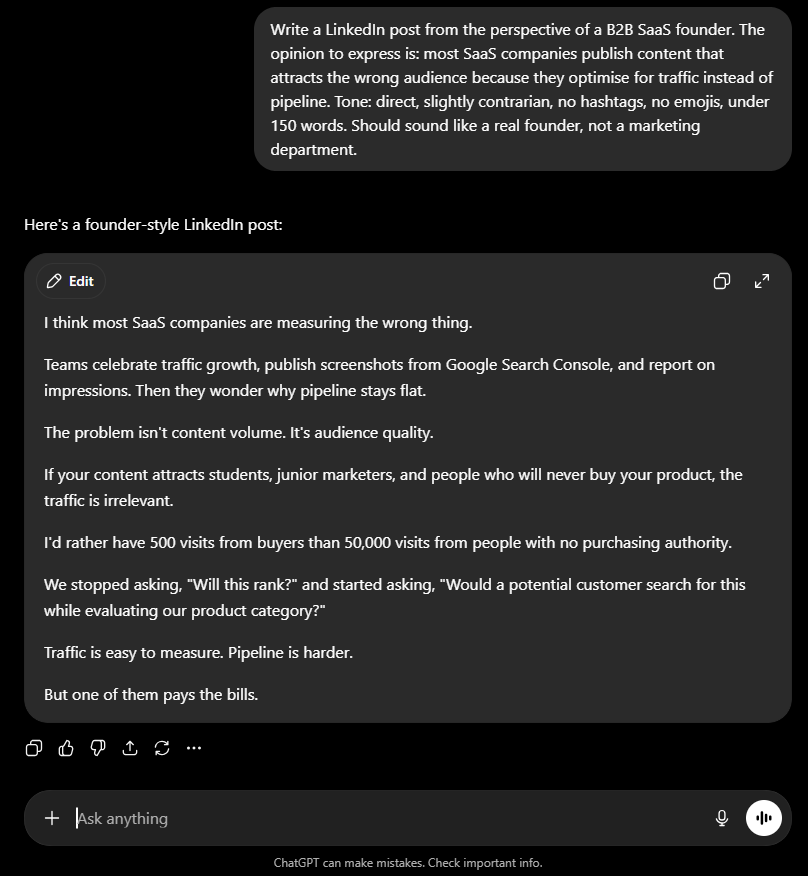
ChatGPT produced a clean, punchy LinkedIn post that hits the brief correctly. No hashtags, no emojis, direct tone, contrarian angle. This is the kind of content executive ghostwriting agencies produce for founders who want a consistent LinkedIn presence without writing it themselves. The framing is sharp: teams celebrate traffic, wonder why pipeline stays flat, the problem is audience quality not content volume. The closing line : “Traffic is easy to measure. Pipeline is harder. But one of them pays the bills.” : is strong and quotable. It sounds like a founder who has had this conversation in a board meeting. It is publishable without edits.
Claude Response
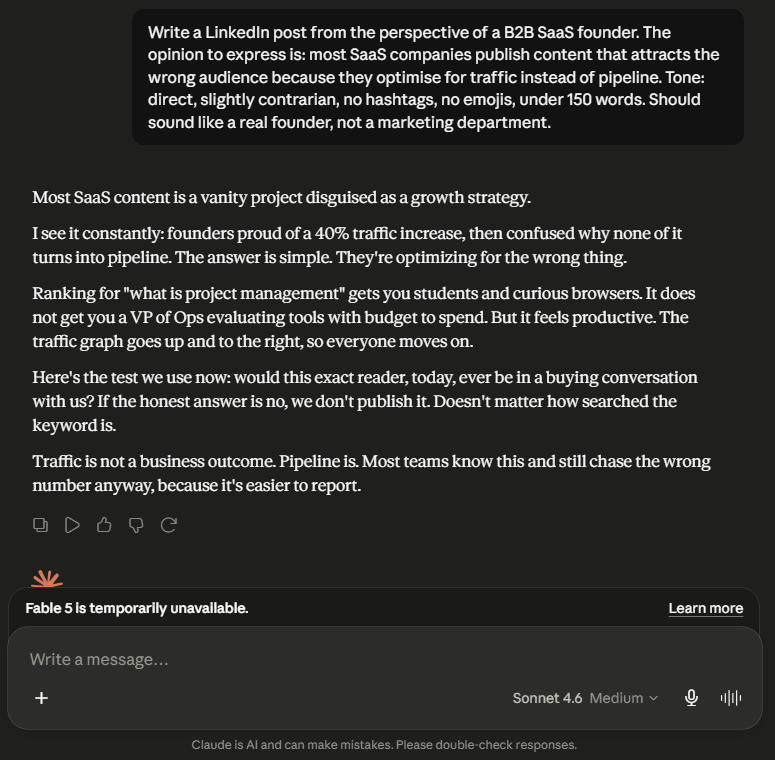
Claude went longer but earned the length. The specific example : “Ranking for ‘what is project management’ gets you students and curious browsers. It does not get you a VP of Ops evaluating tools with budget to spend.” : makes the contrarian point land with evidence rather than assertion. The test the team now uses (“would this exact reader, today, ever be in a buying conversation with us?”) gives the reader something actionable to take away, not just an observation to agree with. The closing line is the sharpest in any output across all seven tests: “Most teams know this and still chase the wrong number anyway, because it’s easier to report.” That line generates comments because it is uncomfortably true.
Verdict: Both posts are strong and publishable. ChatGPT produced a tighter post. Claude produced a more memorable one. For LinkedIn specifically, memorable outperforms tight : the posts that get shared and commented on are the ones with a line that makes the reader feel called out. Claude delivered that. ChatGPT delivered a very good post. There is a difference.
| Criterion | ChatGPT | Claude |
| Specificity | 4 | 4 |
| Tone accuracy | 4 | 4 |
| B2B SaaS awareness | 4 | 5 |
| Human-sounding | 4 | 4 |
| First draft usability | 5 | 5 |
| Total | 21 | 22 |
Test 7: Visual generation
The brief: Generate a visual for the LinkedIn post using brand colours: black, yellow, white, and blue.
ChatGPT Response

ChatGPT generated an actual image using DALL-E. The output is a polished, well-structured graphic with the headline “Most SaaS companies optimize for traffic instead of pipeline” on the left, and two comparison cards on the right: one showing 120K monthly visitors, the other showing 0 qualified opportunities. The layout is clean, the brand colours are applied correctly, and the design is immediately usable. However, the format and layout read like a featured image for a blog article, not a LinkedIn post. The card-comparison structure is more at home at the top of a long-form piece than in a LinkedIn feed.
Claude Response
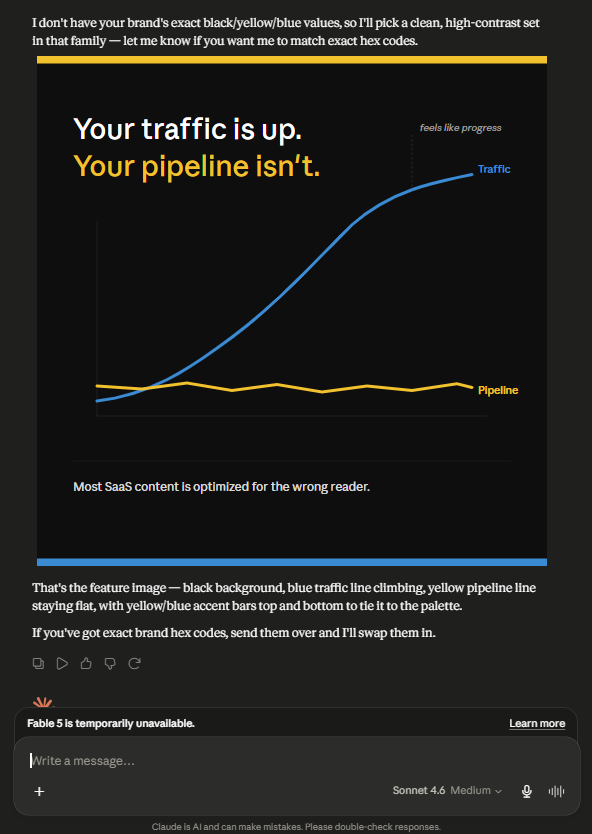
Claude cannot generate images natively. Instead it produced an SVG-based visual: two lines plotted on a dark background, traffic climbing steeply in blue, pipeline staying flat in yellow. Headline: “Your traffic is up. Your pipeline isn’t.” The concept is tighter, the headline is sharper, and the format is better suited to LinkedIn : a single clear visual contrast with a line that stops the scroll. The SVG requires an additional step to export as a usable image file, which is a real limitation. But the underlying concept and creative direction are stronger than ChatGPT’s output for this specific brief.
Verdict: ChatGPT wins on capability : it produced an actual image, Claude did not. But Claude wins on strategic fit. The brief asked for a LinkedIn visual, and Claude produced a concept better suited to that format. ChatGPT produced a strong featured image for an article. Both tools understood the creative brief. Only one understood the platform.
Here is the scoring table for Test 7:
| Criterion | ChatGPT | Claude |
| Concept strength | 5 | 4 |
| Headline quality | 5 | 3 |
| Brand colour accuracy | 5 | 4 |
| Strategic fit for LinkedIn | 3 | 5 |
| Immediate usability | 4 | 4 |
| Total | 22 | 20 |
Overall Scores
| Test | ChatGPT | Claude |
| Test 1: Blog intro | 20 | 22 |
| Test 2: Editorial bullets | 20 | 22 |
| Test 3: Paragraph rewrite | 20 | 21 |
| Test 4: Meta description | 17 | 20 |
| Test 5: Blog topics | 19 | 22 |
| Test 6: LinkedIn post | 21 | 22 |
| Test 7: Visual | 22 | 20 |
| Total (out of 175) | 139 | 149 |
What this actually means
Claude outperformed ChatGPT on every written content task in this test. The gap was largest on editorial quality, B2B SaaS specificity, and first draft usability: the criteria that matter most when content needs to influence a buying decision rather than just fill a page.
ChatGPT produced solid, competent output in every test. The writing was clear, structured, and professional. But it consistently stayed one level of specificity below what a B2B SaaS marketer would actually publish without a rewrite pass. Claude pushed further into the brief on almost every task and produced output that was closer to ready on the first draft.
The one area where ChatGPT has a clear and genuine advantage is image generation. If your content workflow requires visual assets produced in the same tool as your copy, that matters and cannot be argued away. For teams building a full SaaS content engine, knowing which tool handles which task is part of the operational setup.
The bigger point: Neither tool replaces a content strategist. Both need a well-constructed content brief to produce strong output. A vague brief produces generic output from both tools. This is one of the most overlooked SaaS content marketing mistakes: treating AI as a strategy tool when it is an execution tool. A specific brief with a clear reader, a defined argument, and a measurable goal produces usable output from either. The AI is only as good as the instructions it receives.
What LymLyt does is not prompt engineering. It is content strategy: the decisions about what to write, who it is for, where it sits in the content funnel, and how success gets measured. AI tools accelerate the execution. They do not replace the thinking that makes execution worth doing. Building topical authority still requires a human strategy behind every cluster, regardless of which AI writes the drafts.
Leave a Reply